
- 最终成果体验
- 为什么会开始这个项目
- 技术调研
- 前期准备
- 模型训练(train.py)
- 图片识别(predict.py)
- 使用Canvas进行手写输入识别
- 使用Tensorflow JS代替服务端工作
- 后续计划
- 参考资料
最终成果体验
点击在线体验,或直接在下面内嵌的网页中体验:)
为什么会开始这个项目
在玩王国之泪的时候,看到一些海利亚文,总想着识别出来这些海利亚文的含义。手动去查了一下字母对照表,发现不仅难分辨,还有一些重复的,一个字一个字对照未免太累了。

于是想着是不是可以用机器学习的思路将这些图片中的文字自动识别出来的呢?
自己对机器学习只有一些皮毛了解(吴恩达老师的机器学习入门),对于训练模型和OCR完全没有实际工程操作经验,所以就想着先从机器学习的HelloWorld – MNIST入手,先搭建一个识别手写数字的网页。
技术调研
最终的目标是建立一个网页,用户在Canvas画板中用鼠标画出对应的数字,然后对这个图像进行模型识别,将对应的结果输出在网页上的结果区。
其中涉及到以下几个技术点:
-
模型训练:a) 数据集:MNIST是公开的手写数据集,可以提供上万个样本和测试数据; c) 模型选择:CNN和DNN都是不错的选择,通过对比准确度选择目标模型;b) 工程工具:Tensorflow大大简化了模型训练的工作量,几行代码即可完成配置开始训练;
-
图片预处理并输入模型识别:a) 训练好的模型需要可保存,TF提供了对模型的保存能力;b) 图片预处理使用Pillow库和PyNum库可以完成,CV2库也可以做为备选;
-
Canvas手写输入:a) Canvas提供了画图的API,通过鼠标的按下和移动事件,可以画出对应的轨迹,即为手写输入;b) Canvas的内容可以导出成base64传到服务端进行内容识别。
前期准备
在开始项目前,又去大概了解了一下CNN和机器学习相关的基本概念,不过这块后续单独展开。 另外环境的准备也很重要,需要安装Python3 >= 3.6、pip3、以及对应需要用到的python包:(tensorflow>2.0)
// 以下代码既安装了python3也安装了pip3
brew install python3
pip3 install tensorflow opencv-python django-admin Django matplotlib
模型训练(train.py)
首先是准备测试集和训练集,tensorflow集成了这部分的功能,会自动帮助在线下载对应的数据集:
import tensorflow as tf
# 加载mnist数据集,如果本地没有,会从远程下载到目录~/.keras/datasets/下
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
可以使用matplotlib提供的plot能力,来将部分的样本图片进行展示,也可以使用Pillow提供的Image对单张图片进行展示,还能通过对应数据集的shape函数,查看这些数据集的形状(即维度信息):
import matplotlib.pyplot as plt
from PIL import Image
import numpy
def plot_samples(samples, labels, rows, cols):
"""
将样本显示在一张图片上
"""
fig, axs = plt.subplots(rows, cols, sharex="all", sharey="all")
axs = axs.flatten()
for i in range(rows * cols):
# elem = .reshape(28, 28)
axs[i].set_title(labels[i], fontsize=10, pad=0)
# 可以将cmap指定为Greys来展示白底黑字
axs[i].imshow(samples[i], cmap="gray", interpolation="nearest")
axs[0].set_xticks([])
axs[0].set_yticks([])
plt.tight_layout(h_pad=0.5, pad=0)
plt.show()
# 60000个训练集和10000个测试集
# (60000, 28, 28) (60000,) (10000, 28, 28) (10000,)
print(x_train.shape, y_train.shape, x_test.shape, y_test.shape)
# 显示部分训练集和测试集
plot_samples(x_train, y_train, 10, 10)
plot_samples(x_test, y_test, 10, 10)
# 可以使用PIL提供的方法来展示单张图片
pil_img = Image.fromarray(numpy.uint8(x_train[1]))
pil_img.show()
图片展示的结果如下:
| 训练集前100张 | 测试集前100张 | 训练集第二张 |
 |  |  |
准备好数据之后,需要构建模型,例如使用DNN,CNN还是其它的模式来训练。
本次我们使用卷积+全连接的常规方式来构建模型结构:三层卷积,其中每层都进行2x2池化,后接两层全连接,输出10个结果,即0~9的概率,用的softmax。
from keras import layers, models
# 模型定义,3层卷积(Conv2D)池化(MaxPolling2D)+一层全连接(Dense)
model = models.Sequential()
# 第一层需要指定输出的数据尺寸,后面的层通过找推导不需要指定
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
# 第2层卷积,卷积核大小为3*3,64个
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
# 第3层卷积,卷积核大小为3*3,128个
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
构建完模型之后,需要指定损失函数、优化函数以及评估标准等进行编译
# 编译模型(需要配置学习过程),可以指定优化函数、损失函数、评估标准
model.compile(
optimizer=tf.keras.optimizers.legacy.Adam(0.001),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
最后,输入训练样本进行模型训练,其中添加了tensorboard用于生成训练过程中的一些可视化信息,如模型可视化,损失函数去试等。
训练好后需要将模型保存下来,通过summary可以查看模型的概览数据,通过evaluate可以使用测试集查看训练的效果。
import datetime
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
# 归一化处理
x_train, x_test = x_train / 255.0, x_test / 255.0
# 对样本进行训练,可以指定迭代次数和批量大小
model.fit(x_train, y_train, epochs=10, callbacks=[tensorboard_callback])
# 将模型保存到指定目录,后续可以直接使用
model.save("./hand_write_model_with_cnn")
model.summary()
# 评估模型效果
model.evaluate(x_test, y_test, verbose=2)
至此,训练完成,得到的结果如下,可以看到模型运用在测试集上准确度是0.98,可以使用实际的数据进行测试了。
Epoch 1/10
1875/1875 [==============================] - 13s 7ms/step - loss: 0.1922 - sparse_categorical_accuracy: 0.9396
Epoch 2/10
1875/1875 [==============================] - 14s 7ms/step - loss: 0.0673 - sparse_categorical_accuracy: 0.9797
Epoch 3/10
1875/1875 [==============================] - 13s 7ms/step - loss: 0.0494 - sparse_categorical_accuracy: 0.9847
Epoch 4/10
1875/1875 [==============================] - 12s 7ms/step - loss: 0.0372 - sparse_categorical_accuracy: 0.9883
Epoch 5/10
1875/1875 [==============================] - 12s 6ms/step - loss: 0.0299 - sparse_categorical_accuracy: 0.9904
Epoch 6/10
1875/1875 [==============================] - 11s 6ms/step - loss: 0.0228 - sparse_categorical_accuracy: 0.9926
Epoch 7/10
1875/1875 [==============================] - 11s 6ms/step - loss: 0.0187 - sparse_categorical_accuracy: 0.9937
Epoch 8/10
1875/1875 [==============================] - 11s 6ms/step - loss: 0.0166 - sparse_categorical_accuracy: 0.9945
Epoch 9/10
1875/1875 [==============================] - 11s 6ms/step - loss: 0.0140 - sparse_categorical_accuracy: 0.9956
Epoch 10/10
1875/1875 [==============================] - 11s 6ms/step - loss: 0.0130 - sparse_categorical_accuracy: 0.9957
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
max_pooling2d (MaxPooling2 (None, 13, 13, 32) 0
D)
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
max_pooling2d_1 (MaxPoolin (None, 5, 5, 64) 0
g2D)
conv2d_2 (Conv2D) (None, 3, 3, 128) 73856
max_pooling2d_2 (MaxPoolin (None, 1, 1, 128) 0
g2D)
flatten (Flatten) (None, 128) 0
dense (Dense) (None, 64) 8256
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 101578 (396.79 KB)
Trainable params: 101578 (396.79 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
313/313 - 1s - loss: 0.0778 - sparse_categorical_accuracy: 0.9839 - 678ms/epoch - 2ms/step
在当前目录下增加了两个新目录
├── hand_write_model_with_cnn
│ ├── assets
│ ├── fingerprint.pb
│ ├── keras_metadata.pb
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00001
│ └── variables.index
├── logs
│ └── fit
│ └── 20230809-143109
│ └── train
│ └── events.out.tfevents.1691562670.F59M4JW2LL.89510.0.v2
└── train.py
hand_write_model_with_cnn:保存下来的模型,默认情况下保存的类型为TensorFlow SavedModel format(也称为keras_saved_model或者tf类型),除此之后还有h5,keras等类型。
logs:tensorboard用于生成页面的日志数据,在命令行运行tensorboard --logdir logs/fit,就可以在浏览器中访问localhost:6006来查看训练过程中的各个指标了,如下图展示的是loss(损失值)和accuracy(准确度)在每一轮迭代中的趋势。
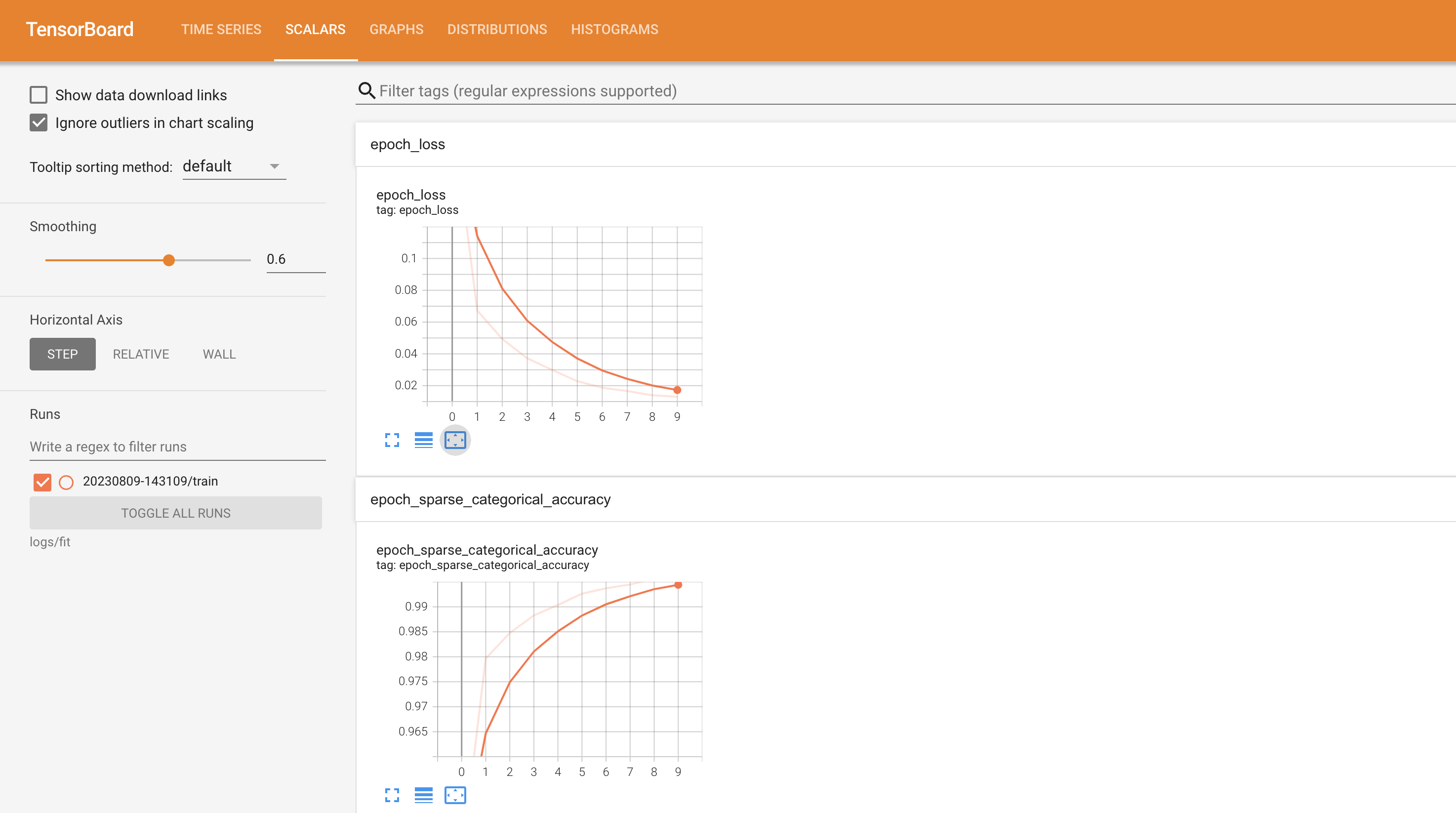
图片识别(predict.py)
在进行图片处理之前,先将保存的模型加载上来:
import tensorflow as tf
# 加载训练好的模型
model = tf.keras.models.load_model('./hand_write_model_with_cnn')
print(model.summary())
对于需要识别的图片,需要对进行标准化,使得与样本中的图片格式一致。这就需要对图片进行预处理。
比如我们随便在某个地方手写了一个数字8,则需要对他进行以下处理,完成如下图的转变
![]()
- 使用PIL库读取图片f = Image.open(file)
- 转化为灰度图片i = f.convert(“L”)
- 大小转化为与样本一样大小28*28:i = i.resize((28, 28))
- 转化为黑底白字 i = ImageChops.invert(i)
- 增加亮度,使得数字的轮廓更明显(可选)i = ImageEnhance.Brightness(i).enhance(factor=bright)
- 然后将图片转化为numpy数组
from PIL import Image,ImageChops,ImageEnhance
import nump
def img_pre_process(file, invert=False, bright=1.5):
# 对图片进行预处理,因为图片是白底黑字,大小不一,所以需要进行一些预处理
f = Image.open(file)
# 转成灰度图片,将原来4维(RGBA)转成一维
i = f.convert("L")
# 缩放图片
i = i.resize((28, 28))
if invert:
# 转成黑底白字
i = ImageChops.invert(i)
if bright > 0:
# 按需求加亮,加对比度等
i = ImageEnhance.Brightness(i).enhance(factor=bright)
# 转化为numpy数组,shape为28*28
return numpy.array(i)
有了预处理函数,那就使用加载好的模型来预测一下效果吧
# 预处理图片,然后转化为ndarray处理
img9 = img_pre_process("./9.png", bright=0)
samples = [img9 / 255]
img3 = img_pre_process("./3.png", invert=True, bright=0)
samples.append(img3 / 255)
img6 = img_pre_process("./6.png", invert=True)
samples.append(img6 / 255)
img6 = img_pre_process("./8.png", invert=True)
samples.append(img6 / 255)
# 由于predict的输入是批量的,所以这块的shape为n*28*28,n为样本数量
res = model.predict(numpy.array(samples))
# 结果为对各个样本的概率预测结果,以上结果如下
# [[4.5536960e-12 8.6428139e-12 2.2465254e-12 1.1361015e-09 1.4199172e-07
# 1.1165924e-10 1.2581486e-14 3.7364101e-10 3.2622338e-09 9.9999988e-01]
# [3.4697410e-12 4.4372114e-06 1.4305875e-06 9.9997211e-01 3.2144427e-09
# 3.2603787e-06 1.4439445e-12 1.7748405e-05 5.1269499e-11 9.1026078e-07]
# [5.4244672e-05 1.5443358e-05 2.2776185e-05 7.1670558e-10 7.0248444e-07
# 2.8083429e-03 9.9709213e-01 4.1633821e-10 4.8526099e-06 1.4761381e-06]
# [8.4286776e-18 8.2335221e-14 1.3553557e-11 2.5355894e-14 6.0165419e-17
# 2.1572887e-15 1.5686732e-14 9.7833466e-15 1.0000000e+00 1.2415943e-15]]
print(res)
结果可以看出,4张图片预测全部预测对了,成功率为100%。
使用Canvas进行手写输入识别
一张一张图片截图下载写代码去识别这种方式未免显得太麻烦,如果能在网页上直接手写,通过提交快速识别出来,不仅可以快速进行测试,也能为后续的训练提供更多的样本数据。
首先需要解决canvas手写的问题,基本思路是在canvas中监听鼠标事件,在鼠标按下时,记录当前的坐标(x,y),通过监听移动事件,在移动到新的位置(newx,newy),在(x,y)到(newx,newy)之间画一条直线,这样基本可以达到手写的目的,其代码如下:
<canvas id="myCanvas" width="100" height="100"></canvas>
<script>
const c = document.getElementById("myCanvas");
const ctx = c.getContext("2d");
let x = 0;
let y = 0;
c.onmousedown = function (e) {
x = e.offsetX
y = e.offsetY
c.onmousemove = function (e) {
const newX = e.offsetX;
const newY = e.offsetY;
ctx.lineWidth = 10
ctx.moveTo(x, y)
ctx.lineTo(newX, newY)
ctx.stroke()
x = newX
y = newY
}
}
c.onmouseout = function (e) {
c.onmousemove = null
}
c.onmouseup = function (e) {
c.onmousemove = null
}
</script>
<style>
#myCanvas {
border: 1px solid rgb(103, 194, 58);
box-shadow: 0 2px 4px rgba(103, 194, 58, .12), 0 0 6px rgba(103, 194, 58, .1);
}
</style>
有了手写输入,就需要考虑后端识别了,为了简单起见,使用Python的Django快速建了个本地的站点。在项目目录上运行django-admin startproject hand_write_site命令,创建名为hand_write_site的网站。在根目录多了以下文件。
├── hand_write_site
│ ├── hand_write_site
│ │ ├── __init__.py
│ │ ├── asgi.py
│ │ ├── settings.py
│ │ ├── urls.py
│ │ └── wsgi.py
│ └── manage.py
首先,在__init__.py中加载模型
import tensorflow as tf
print("loading model...")
model = tf.keras.models.load_model('../hand_write_model_with_cnn')
print("load model finished.")
添加views.py文件,实现以下两个接口:
index:首页,用于展示手写内容,直接加载template即可
submit: 处理客户端提交的图片,也就是手写识别的关键流程
from django.http import HttpResponse
from django.shortcuts import render
from PIL import Image, ImageChops
import numpy, io, json, base64
from . import model
def index(request):
return render(request, 'index.html', {})
def submit(request):
# canvas图片的数据会转化为base64通过post的data传过来,但这块会有一些前置的信息,需要去除
base64_str = request.POST['data'].split(",")[1]
# print(base64_str)
# base64的图片信息转化为Image
raw = Image.open(io.BytesIO(base64.decodebytes(bytes(base64_str, "utf-8"))))
# 由于传过来的image是个PNG,背景是透明的,所以不能直接转灰度,需要将其copy到一张带白底的图上
img = Image.new('RGB', raw.size, (255, 255, 255))
img.paste(raw, (0, 0), raw)
# 然后对图片进行预处理
img = img.convert("L")
img = img.resize((28, 28))
img = ImageChops.invert(img)
# img.show()
# 模型预测
predict = model.predict(numpy.array([numpy.array(img) / 255]))
# 将处理完的图片转成base64返回
output_buffer = io.BytesIO()
img.save(output_buffer, format='JPEG')
base64_data = str(base64.b64encode(output_buffer.getvalue()), 'utf-8')
# 同时返回预测结果和处理后的图片
return HttpResponse(json.dumps(
(predict.tolist(), base64_data)
))
其它配套的文件改动:
urls.py,红色为新加路由
from django.contrib import admin
from django.urls import path
from . import views
urlpatterns = [
path('admin/', admin.site.urls),
path('index/', views.index),
path('submit/', views.submit),
]
settings.py中去掉django.middleware.csrf.CsrfViewMiddleware中间件,防止AJAX提交的时候报CSRF错。由于需要用到模板,所以需要在模板配置中添加对应的目录:
import os
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
# 'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
ROOT_URLCONF = 'hand_write_site.urls'
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR, 'templates')],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
在外层新建templates目录,添加index.html,做为展示手写输入、提交以及展示结果的页面。
templates/index.html
// 省略大部分代码,只展示ajax处理的代码
$.post("/submit/", {"data": c.toDataURL("image/png")},
function (data) {
// 计算最大值,并拼接表格数据
let m = -999.0;
let i = -1;
let predict_table_percent = "";
// data[0]是预测结果,但是由于支持批量,所以需要再取一层data[0][0]
// data[1]为服务端处理的图片的base64值
data[0][0].forEach((v, k) => {
if (v > m) {
m = v
i = k
}
predict_table_percent += "<td>" + Math.round(v * 10000) / 100 + "%</td>"
}
)
$("#predict-label").html("预测值:" + i + ",概率:" + Math.round(m * 10000) / 100 + "%,处理后的图片:")
$("#predict-table tr").last().html(predict_table_percent)
// 高亮表格中预估值
let tds = $("#predict-table td")
tds.css("background-color", "").css("color", "")
tds.eq(i).css("background-color", "#f0f9eb").css("color", "#67c23a")
tds.eq(i + 10).css("background-color", "#f0f9eb").css("color", "#67c23a")
// 将处理的图片显示在上面
$("#pre_process").attr("src", "data:image/jpeg;base64," + data[1])
}, "json"
)
这样,在site目录下运行python3 manage.py runserver 0.0.0.0:8000,就能在浏览器中打开localhost:8000看到效果了
使用Tensorflow JS代替服务端工作
之前的例子中,需要服务端具备图片处理能力以及运行模型的能力,这对于没有服务端处理能力的(如github的pages)以及非Python的服务端运行模型带来了难度。是否可以基于浏览器进行图片处理和模型处理呢?
TensorflowJS提供了解决方案,它能够在网页中训练模型、加载模型、预测结果,这正是我们想要的,接下来我们将使用tfjs在浏览器中运行模型预测。
注:由于CROS存在,所以无法纯本地运行对应的网页内容,还是需要一个server来承接,不过server的要求就很低了,一个简单的nginx即可满足要求。
首先,将由python保存的模型转化为tfjs能识别的模型
# 下载tensorflowjs包,这会一并把tensorflowjs_converter转化工具也下载了
pip3 install tensorflowjs
# 使用tensorflowjs_converter,将python的模型转化为tfjs可识别的格式
tensorflowjs_converter --input_format keras_saved_model ./hand_write_model_with_cnn ./hand_write_model_with_cnn_tfjs
生成的hand_write_model_with_cnn_tfjs目录包含有两个文件,model.js和对应的参数bin文件
├── hand_write_model_with_cnn_tfjs
│ ├── group1-shard1of1.bin
│ └── model.json
当然在网页上也少不了导入对应的js库以及初始化加载model
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js"></script>
<script>
let model
tf.loadLayersModel('./hand_write_model_with_cnn_tfjs/model.json').then(function (m){
model = m
})
</script>
然后在网页中对Canvas的图片进行处理,主要步骤是1. 缩放,2. 灰度化,3. 反相
缩放:借助辅助的Canvas来处理
// 处理图像
// 获取辅助的Canvas
const shadow = document.getElementById("shadowCanvas");
const shadow_ctx = shadow.getContext("2d");
// 由于背景是透明的,在处理灰度时会有问题,所以先填充上背景
shadow_ctx.fillStyle = "white"
shadow_ctx.strokeStyle = "white"
shadow_ctx.fillRect(0, 0, 28, 28)
// 将手写的图像复制到辅助Canvas上,指定宽高从而实现缩放
shadow_ctx.drawImage(c, 0, 0, 28, 28);
灰度化和反相,都是处理像素点数据,所以合并在一个流程中进行处理了
// 取出像素值,对像素值进行数值计算,来达到灰度化和反相的目的
const imageData = shadow_ctx.getImageData(0, 0, 28, 28)
const data = imageData.data;
for (let i = 0; i < data.length; i += 4) {
// 使用平均值法取灰度,并使用255-平均值取反相
const avg = 255 - (data[i] + data[i + 1] + data[i + 2]) / 3;
data[i] = avg; // red
data[i + 1] = avg; // green
data[i + 2] = avg; // blue
}
shadow_ctx.putImageData(imageData, 0, 0);
处理完这个辅助Canvas之后,将此图像转移到img标签中,然后再从这个标签中处理预测
// 将辅助Canvas的图像展示到pre_process上,后续对这个图像做模型预估即可
$("#pre_process").attr("src", shadow.toDataURL("image/png")).one("load", function () {
predict()
})
async function predict() {
const raw_data = tf.browser.fromPixels(document.getElementById("pre_process"), 1).div(255.0);
const prediction = model.predict(raw_data.reshape([1, 28, 28, 1]));
prediction.print()
let m = -999.0;
let i = -1;
let predict_table_percent = "";
prediction.dataSync().forEach((v, k) => {
predict_table_percent += "<td>" + Math.round(v * 10000) / 100 + "%</td>"
if (v > m) {
m = v
i = k
}
}
)
// 省略UI处理
}
后续计划
这个项目的初衷是识别海利亚文,完成这个例子之后,对于机器学习工程上的使用,基本可以顺下来。但还面临着以下一些问题:
-
如果何使用少量的样本学习出好的效果。海利亚文的样本数据没有,需要自己去创建;目前了解到的方法是自己通过合成的样本的方式来实现,还可以调研一下GAN(对抗神经网络)的原理,看是否可应用;
-
OCR的思路不是很清晰,如果使用之前吴恩达课程中了解到的方法,那需要训练的模型较多,所需要的样本量比较大;
第一个问题可能是更棘手的问题,所以下一步是通过生成样本的形式,训练出可以自动识别海利亚文的模型,然后使用真实的游戏截图人工处理文字区域来判断模型的准确率。
参考资料
- 机器学习
- Python
- Javascript语法
- TensorFlow
- 图片处理
- OCR
- 其它