第5章 初使化和清理
-
在构造函数中调用父类构造函数,必须置于最起始处,并且只能调用一个父类构造函数。
-
构造器实际上是static的。
-
finalize方法与析构函数不同,是在垃圾回收时调用;而垃圾回收的时机是不确定的。
垃圾回收器的工作方式
引用计数
每一个对象含有一个引用计数器,当引用接至对象时,计数加1,当离开作用域或者设置成null时,计数减1。这样垃圾回收器在全部队象列表遍历,释放计数为0的对象空间。
特点是简单,但速度慢,还有循环计数的问题。所以在Java虚拟机中未被应用。
引用链条
从栈和静态存储区开始,遍历所有的引用,这些能被遍历到的对象就是活的对象,没有被遍历到的对象应该被回收。这种思想下有两种JVM实现:
停止-复制
暂停所有程序运行,然后将所有活的对象复制到另一个堆,没有被复制的就是垃圾资源。复制后的对象在新堆中紧凑排列,所以此时可以使用堆指针的方式简单分配内存。
问题:1. 必须修正所有引用;2. 更费内存空间,至少double;3. 复制本身的开销;
标记-清除(mark and sweep)
第一遍对所有遍历到的引用进行标记,在标记工作完成后,进行清除。这导致剩下的堆空间非连续,同时这一工作也必须暂停程序才可以执行。
自适应垃圾回收器
将内存分块,并对每一个分块记录代数。JVM会监视停止复制或者标记清除的效率,根据结果在这两种策略之间进行自适应切换。
其它附加技术用以提升速度
如JIT,HotSpot使用惰性评估的方式,在每一次执行之后进行一些优化,运行越多次,速度越快。
第6章 访问权限控制
类的访问权限默认(即没有修饰)为包访问权限,即同一个包内的可访问。类一般不可声明为protected或者private,除非是内部类。
没有包名的类都处于同一个默认包名中,所以他们被视为同一个包内。
第7章 复用类
当创建一个导出类的对象时,该对象包含一个基类的子对象。
对于基类构造函数的调用,如果是显式的,必须在导出类构造函数的第一行。
向上转型,即将导出类转型为基类型,名称的由来是由于在画继承图时的方向是向上的。向上转型被认为是安全的,会丢失一些信息。
选择使用组合还是继承的一个清晰判断办法是问一问自己是否需要从新类向上转型到基类。如果需要,则使用继承,否则可以考虑放弃继承使用组合。
既是final又是static的域称之为编译期常量,使用全大写表示,单词之间下划线分割。
当final修饰的是引用时,表明这个引用指向无法改变,但引用对象本身是可以变的,例如可以改变这个引用指向对象的成员变量值等。
当函数参数被final修饰时,表明这个参数不可变。
private的方法默认是final的,我们可以在导出类上实现基类中的private方法是因为做为private方法,他并不是基类接口的一部分,此时导出类实现的并没有覆盖基类的方法,而是生成了一个新的方法。
第8章 多态
域(属性成员)和静态方法不具有多态性。
构造函数的调用顺序
在其它任何事物发生之前,将分配给对象的存储空间初始化为二进制的零;
调用基类构造器,递归下去,直到调用到Object的构造器为止;
按声明顺序调用成员的初始化方法;
调用导出类的构造器主体。
在构造器中调用多态的方法的行为
如果这个调用是在父类中出现,会出现在导出类成员没有初使化完成的情况下调用了导出类的方法,会有一些非预期的行为。如下例子:
public class Base {
public Base() {
f();
}
public void f() {}
public static void main(String[] args) {
new Heris(20);
// Heris i:0
// Constructor i:20
}
}
class Heris extends Base {
public int i = 10;
public Heris(int i) {
super();
this.i = i;
System.out.println("Constructor i:" + this.i);
}
@Override
public void f() {
System.out.println("Heris i:" + i);
}
}
用继承表达行为间的差异,并用字段表达状态上的变化
第9章 接口
接口也可以包含域,但这些域隐匿地是static和final的。
组合接口时的名字冲突:如果两个接口具有相同的方法签名只有返回值不同时,同时实现这两个接口将导致编译器报错。
第10章 内部类
当外围类的对象创建了一个内部类对象时,内部类对象会捕获一个指向外围类对象的引用。所以内部类对象可以使用这个引用来访问外围类的成员,包括私有的成员。
所以在内部类为非static类时,无法在外围内没有被创建的情况下单独创建内部类。
内部类对象访问外部类对象时,可以使用外部类名加.this来获取外部类的引用;创建内部类对象时,使用外部类对象.new后接内部类名来创建内部类对象:
public class InnerClass {
public class Sub{
public InnerClass f(){
return InnerClass.this;
}
}
public static void main(String[] args){
InnerClass innerClass = new InnerClass();
InnerClass.Sub sub = innerClass.new Sub();
System.out.println(sub.f() == innerClass); // true
}
}
如之前所说,内部类对象无法单独创建,即无法使用InnerClass.Sub sub = new InnerClass.Sub();来创建内部类对象。
但如果创建的是一个嵌套类(静态内部类),则不需要依赖于外部类对象,可以直接创建内部类对象。
内部类与向上转型
可以使用内部类实现某一个接口,来隐藏实现的细节,并提供向上转型成某个接口或者基类的能力:
public class Hidden {
private class MyFly implements Flyable {
@Override
public void fly() {}
}
public MyFly myFly(){return new MyFly();}
public static void main(String[] args){
Flyable flyable = new Hidden().myFly();
}
}
interface Flyable {
void fly();
}
方法里的内部类
可以在方法里定义内部类,这个内部类只能在方法里使用。
public class Func {
public static void main(String[] args){
class InnerFunc{}
System.out.println(new InnerClass());
}
}
匿名内部类
在函数内部将继承和实例化合二为一的写法,就是常用的匿名内部类的写法:
public static void main(String[] args){
new Flyable(){
@Override
public void fly() {
}
};
}
嵌套类
将内部类声明为static,则这个内部类称之为嵌套类,它与外围类对象之前的联系不是很紧密,可以单独使用。
public class InnerClass {
public static class StaticSub {}
public static void main(String[] args) {
StaticSub staticSub = new InnerClass.StaticSub();
}
}
另外需要说明的是在接口内部是可以创建嵌套类的,而且只能是嵌套类(static的类)。
关于内部类的特性:不管内部类被嵌套了几层,它总是能访问到所有外围类的成员。
public class Multi {
void f(){}
class Inner1{
void f1(){}
class Inner2{
void f2(){
f();
f1();
}
}
}
}
为什么使用内部类
使用内部类可以实现类似多重继承:
class A {}
class B {}
class C extends A{
B makeB(){
return new B(){
};
}
}
做为额外的好处,内部类还可以创建同一个接口/类的不同实现。
内部类在基于事件回调的GUI编程上得到广泛应用,而且内部类可以获取外围的特性使得实现变得不那么笨拙。
内部类的继承
由于内部类对象必须持有外围对象的引用,所以使用常规方法继承内部,需要使用下面这样语法:外围类对象通过构造函数传入,并调用其super()方法。
class D{
class E{}
}
class F extends D.E{
public F(D d) {
d.super();
}
}
内部类的标识
内部类产生的class文件的命名规则为:外围类的名字,加上$,再加上内部类的名字。
如果内部类是匿名的,编译器会简单产生一个数字做为其标识符。
第11章 持有对象
围绕下图,介绍一下基本的容器关系:
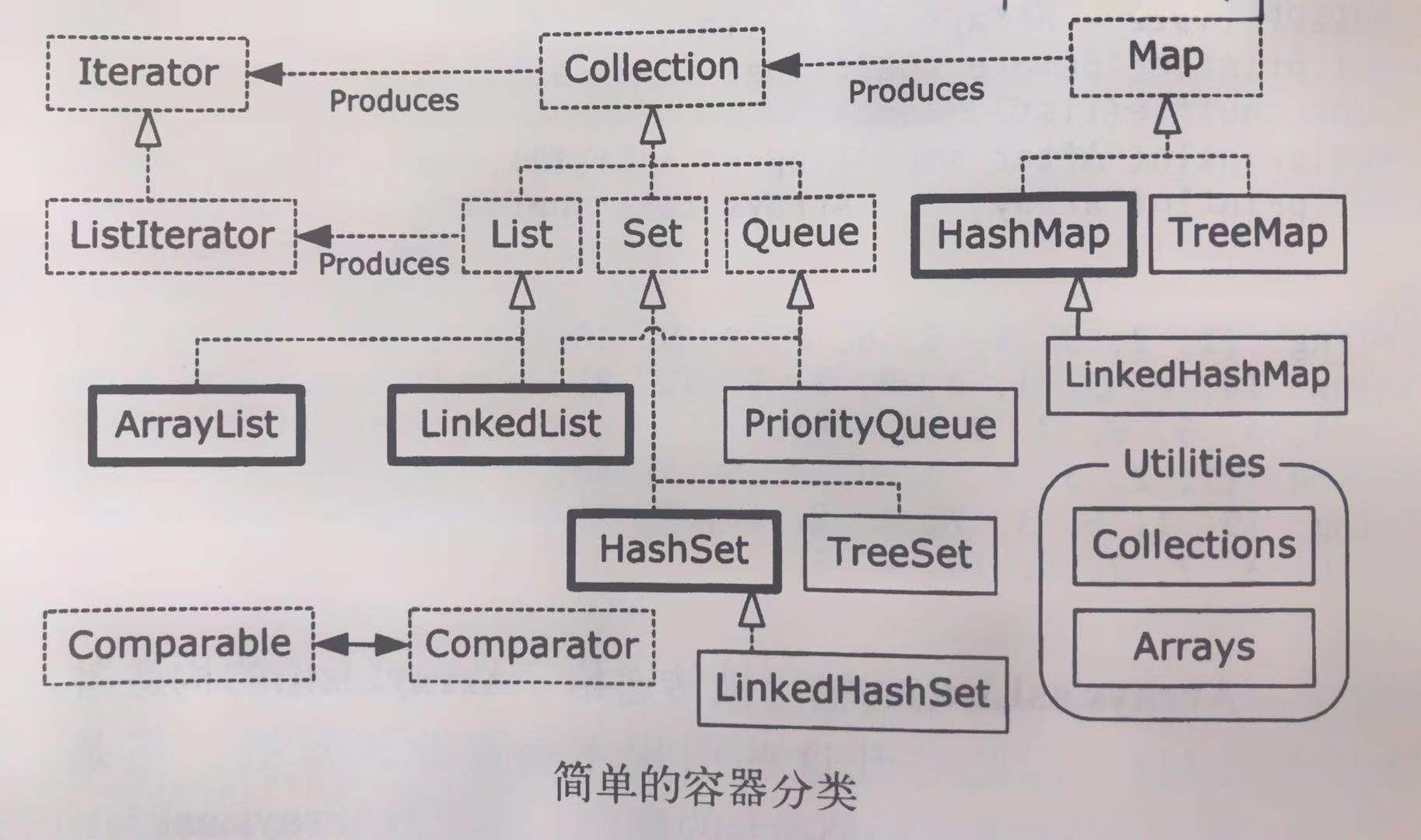
整体来说容器主要分为两大类:Collection和Map。
Collection下又分为List、Set、Queue;具体实现上LinkedList实现了Queue和List的全部功能,而ArrayList只实现了List的功能,支持随机访问。优先队列的实现为PriorityQueue。Set的实现有HashSet和TreeSet。为了实现有序的Set,在HashSet上又扩展实现了LinkedHashSet。
Map的结构比较简单,包括最常用的HashMap和TreeMap,LinkedHashMap是在HashMap的基础上添加一个链表实现的有序Map。
Collection继承自Iterator,所以原生实现了迭代器功能,可以在foreach中使用。Map的通过keySet、entrySet提供一个键/值的Set集合来间接地实现元素的迭代。在1.8之后也可以使用forEach来实现迭代。值得一提的是List提供了一个ListIterator这一可前后移动的更强大的迭代器。
另外两个工具类也是被我们常常使用:Arrays和Collections;他们提供了操作数组或者集合常用的一些方法,如排序、搜索等。
再细看上图,图中常用的容器,使用黑色粗线框表示,有ArrayList、LinkedList、HashMap、HashSet等。点线框表示接口,实线框表示具体的类。带有空心箭头的点线表示对应的类实现了指向的接口。实心箭头表示某个类可以生成所指向类的对象。
第12章 通过异常处理错误
异常类型的根类是Throwable。从Throwable继承得到两种类型:1. Error用来表示编译时和系统错误,一般我们不需要关心;2. Exception是可以抛出的异常基类。
异常对象的printStackTrace函数可以指定错误输出到哪里,默认为输出到System.err,可以使用e.printStackTrace(System.out)来将异常输出到标准输出。
方法声明中的异常说明在Java中是强制的,除了RuntimeException继承的异常,其它所有可能在函数中抛出的异常都必须写在方法声明中。
有时候我们在捕获异常之后,会重新使用这个捕获的异常对象将其抛出,此时需要注意异常中带有的调用栈信息并没有更新,记录的是之前抛出的地方。可以调用异常对象的fillInStackTrace方法来重新设置栈信息。
在Java1.4之后,允许在异常构造器中添加原始异常使用为cause参数(只有Error、Exception、RuntimeException的构造函数有这个参数),也可以在异常上调用initCause来设置这个字段。这样在异常输出时会带有一个Cause by的信息输出。
public class MyException extends Exception {
public static void main(String[] args) throws MyException{
try {
MyException.f();
}catch (MyException e){
e.initCause(new NullPointerException());
throw e;
}
}
public static void f() throws MyException{
throw new MyException();
}
}
/**
Exception in thread "main" thinkinjava.MyException
at thinkinjava.MyException.f(MyException.java:13)
at thinkinjava.MyException.main(MyException.java:6)
Caused by: java.lang.NullPointerException
at thinkinjava.MyException.main(MyException.java:8)
*/
RuntimeException是由JVM抛出的,一般不需要程序中显示抛出和显示声明,这种异常称为不受检查异常。例如NullPointerException在遇到空指针调用时JVM会自动抛出。
finally子句总是会被执行,即使在try中已经return的情况。finally可以执行一些打开文件的关闭、重置状态等操作。值得一提的是在finally中使用return语句,将会丢失所有的异常信息。
在覆盖基类方法时(override),只能抛出在基类异常说明明列出的那些异常。
异常使用指南,在如下情况下可以使用异常:
在恰当的级别处理问题,在知道如何处理的情况下才捕获异常;
解决问题并重新调用产生异常的方法;
进行少许的修补,然后绕过异常发生的地方继续执行;
用别的数据进行计算,以代替方法预计会返回的值 ;
把当前运行环境下能做的事情尽量做完,然后把相同的异常重抛到更高层;
把当前运行环境下能做的事情尽量做完,然后把不同的异常抛到更高层;
终止程序;
进行简化,即使用异常可以简化问题的处理;
让类库和程序更安全。
第13章 字符串
String对象是不可变的,任何对于String的修改都会创建一个新的String对象。
对于使用加号连接两个String对象的操作,编译器会优化为使用StringBuilder对象及append方法进行拼接,相当于编译器的优化。但这仅限于一般场景。所以如果要进行字符串的拼接操作推荐使用StringBuilder创建字符串。
String上提供了一些常用的操作,包括获取长度、判等、比较、子串、查找、连接、替换等等函数,不再一一介绍了。
Strings工具类上实现了类似C语言的sprintf函数Strings.format方法。
String对象上的match和split等函数都支持正则表达式。
如果需要更强大的正则表达式的功能,可以使用java.util.regex里提供的各种方法和类。
第14章 类型信息
Java中使用Class这类特殊对象来表示运行时类型信息(RTTI(Run-Time Type Identification))。
对应类的Class对象在类被加载时创建,可以使用Class.forName("ClassName")来查找ClassName类的Class对象。注意这将触发类的加载,静态成员将被初使化,static子句会被执行。如果找不到对应的类,则产生ClassNotFoundException。
也可以通过类对象的getClass方法获取这个类的Class对象。
Class对象有许多有用的方法,例如获取父类(getSuperclass),获取实现的接口(getInterfaces),获取全限定名(getCanonicalName)或者简单名称(getSimpleName),创建对象(newInstance)等等。
另外一种更加安全方便的方法获取Class对象,是通过类的字面常量来实现的。例如MyClass.class,boolean.class等。这适用于普通类型和基本类型。对于基本类型的封装类,还有一个TYPE字段可以拿到Class对象。
System.out.println(boolean.class == Boolean.class); //false
System.out.println(boolean.class == Boolean.TYPE); // true
使用字面常量来获取Class对象时,并不会自动地初始化Class对象。初始化被延迟到对静态方法或者非常数静态域进行首次引用时。
使用Class对象可以使用强制类型转换,例如用来使用(MyClass) o这样的语法将对象o转化成MyClass,现在可以使用MyClass.class.cast(o)来实现。这在只有Class对象的情况下变得有用。
总结起来Java中的RTTI,其使用形式表现在以下方面:
在强制类型转化中,RTTI确保类型转换的正确性;
代表对象类型的Class对象提供运行时所需要的信息;
为使用instanceof关键字做为类型判断时依据。
instanceof的另外一个替代方法是使用Class对象中的isInstance方法来判断:
A a = new C();
System.out.println(a instanceof C);
System.out.println(C.class.isInstance(a));
Java中的反射是运用Class对象和java.lang.reflect类库对其提供支持的。从下面的例子中可以看出私有的方法还是可能通过反射的方式被外部调用到。
public class MyReflect {
public static void main(String[] args) {
for (Method m : P.class.getMethods()) {
System.out.println(m);
}
System.out.println("============");
for (Method m : P.class.getDeclaredMethods()) {
System.out.println(m);
}
try {
Method m = P.class.getDeclaredMethod("f");
m.invoke(new P());
}catch (NoSuchMethodException e){
System.out.println("no such method!");
}catch (IllegalAccessException |InvocationTargetException e){
System.out.println(e.toString());
}
try {
Method m = P.class.getDeclaredMethod("f");
m.setAccessible(true);
m.invoke(new P());
}catch (NoSuchMethodException e){
System.out.println("no such method!");
}catch (IllegalAccessException |InvocationTargetException e){
System.out.println(e.toString());
}
}
}
class P {
private void f(){
System.out.println("private method f call");
}
}
/**
public final void java.lang.Object.wait(long,int) throws java.lang.InterruptedException
public final native void java.lang.Object.wait(long) throws java.lang.InterruptedException
public final void java.lang.Object.wait() throws java.lang.InterruptedException
public boolean java.lang.Object.equals(java.lang.Object)
public java.lang.String java.lang.Object.toString()
public native int java.lang.Object.hashCode()
public final native java.lang.Class java.lang.Object.getClass()
public final native void java.lang.Object.notify()
public final native void java.lang.Object.notifyAll()
============
private void thinkinjava.P.f()
java.lang.IllegalAccessException: Class thinkinjava.MyReflect can not access a member of class thinkinjava.P with modifiers "private"
private method f call
*/
第15章 泛型
见此篇有详细的介绍。
第16章 数组
Java的数组为容量不可变数组,其性质与其它语言的数组类似,这里不再细说,只是Arrays工具类提供了很多数组相关的操作如排序,复制等等,有需要可以在里面找找。
第17章 容器深入研究
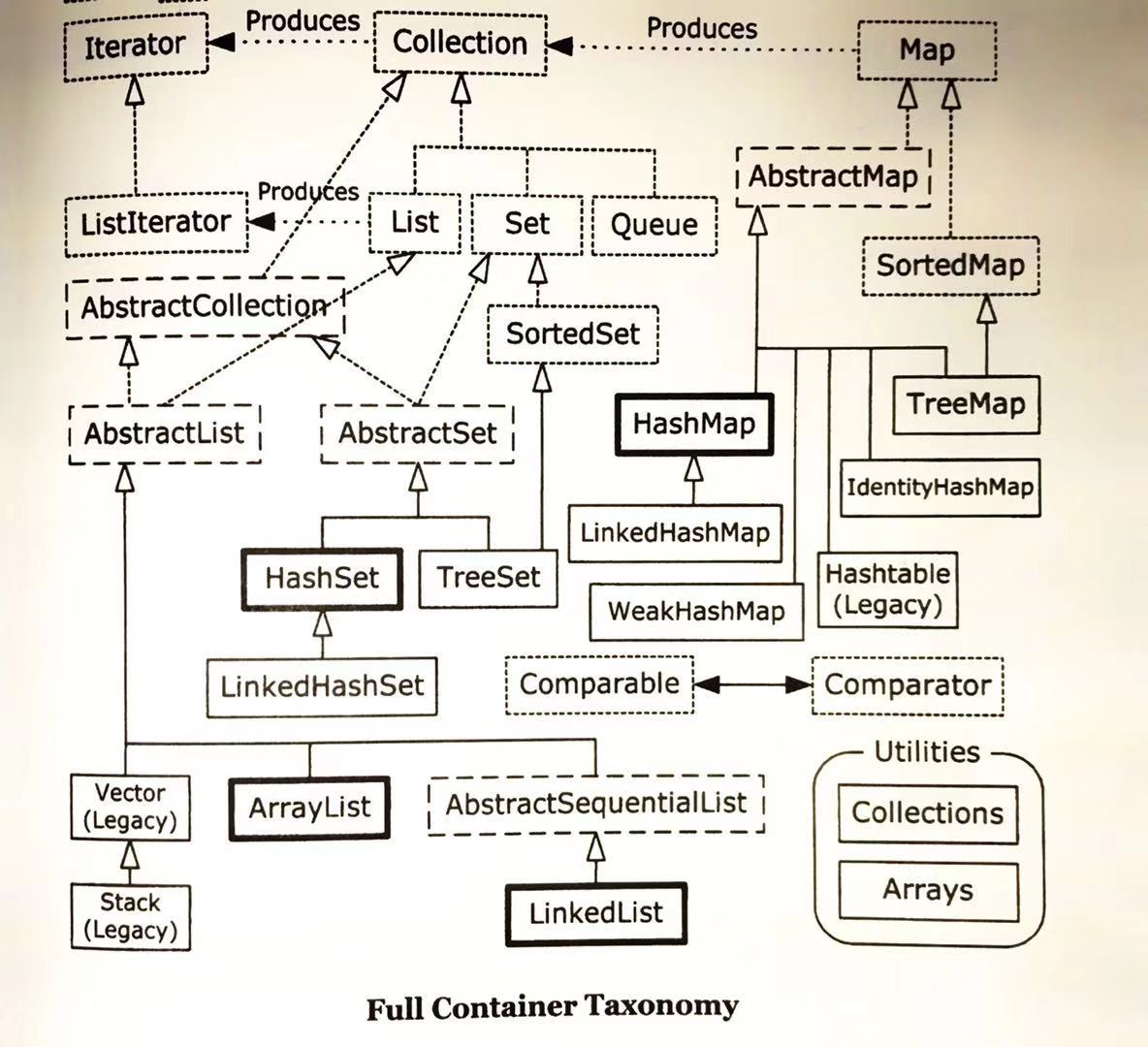
围绕上图,在原来简单的结构图中加入了一些抽象类和遗留组件(Legacy)。
存入Set中的元素必须是唯一的,所以加入Set的元素必须定义equals()方法以确保对象的唯一性。
存入HashSet的元素必须定义hashCode()。
TreeSet内部是有序的,所以他实现了SortedSet。
Map
HashMap: 默认应该使用的Map实现。基于散列表,通过构造器可以设置容量和负载因子,以调整容器的性能。
LinkedHashMap:在HashMap的基础上添加链表来维护一定次序。这个次数可以在构造函数时指定为最近一次访问顺序,还是插入次序。
TreeMap:基于红黑树实现,它是排序的,实现了SortedMap。
WeakHashMap:弱键映射,允许释放映射所指向的对象。如果映射之外没有引用指向某一个键,则这个键可以被回收。
ConcurrentHashMap:线程安全的Map,不涉及同步加锁。在并发一章中讨论。
IdentityHashMap:使用==代替equals()对键进行比较的散列映射。专为解决特殊问题而设置。
对于HashMap的key,其实现的equals()方法和hashCode()方法必须是有意义的。想象一个散列表,hashCode()相同的key落在同一个槽上,使用链表连接,而如何判断这两个key相等就依赖于equals方法了。
对于equals函数的实现要求:
自反性:对任意的x,x.equals(x)一定返回true;
对称性:对于x和y,x.equals(y)返回true,则y.equals(x)一定返回true;
传递性:x.equals(y)与y.equals(z)都为true,则x.equals(z)一定返回true;
一致性。对任意的x和y,如果对象中用于等价比较的信息没有改变,则无论调用x.equals(y)几次,都返回一样的结果;
对于任何不为null的x,x.equals(null)一定返回false。
对于hashCode()函数实现的指导:
假设最后的hashCode为result,先将result赋一个初始值,例如17。
对于对象内第一个有意义的域f,计算出一个int散列值c。例如boolean类型的话,c = f?0:1;非基本类型的话,c = f.hashCode()等等。
将c合并到散列码中 37 * result + c;这时原37与17一样,随便选一个定值。
计算完所有有意义的域后,返回result。
Collections里的一些工具方法
Collections提供了一些返回不可修改的Map或者List的方法,例如public static <K,V> Map<K,V> unmodifiableMap(Map<? extends K, ? extends V> m),这个函数返回的Map在put的时候会抛出UnsupportedOperationException异常。
还有一些同步操作的方法如public static <T> List<T> synchronizedList(List<T> list),则返回的List就是一个线程安全的List了。
快速报错
Collection<String> c = new ArrayList<>();
Iterator<String> it = c.iterator();
c.add("aaa");
String s = it.next(); // 抛出ConcurrentModificationException异常
如果在迭代过程中,有人修改了容器的内容,就会抛出ConcurrentModificationException异常。使用ConcurrentHashMap、CopyOnWriteArrayList和CopyOnWriteArraySet则可以一定程度上避免个异常。
持有引用(弱引用)
java.lang.ref类库中包含了可以提供强度有所区别的引用类型,这里的强度是指引用的强度,与被垃圾回收的可能性成反比。
共有三种引用SoftReference(软引用)、WeakReference(弱引用)和PhantomRefrence(虚引用),从引用的强到弱排列。可参考此。
容器中实现的WeakHashMap就是用来保存WeakReference的。其键和值会自动被垃圾回收器回收。
第18章 Java I/O系统
@todo
第19章 枚举
静态导入:一般的import导入只能导入到类,而静态导入(static import),可以导入到类的静态成员和静态方法,这在枚举中经常使用。
switch如果使用枚举,case中不必写对应的枚举类型如(Signal.RED),而直接写对应的枚举值(RED)。
枚举类型在编译时,编译器会添加一些方法,如values,valueOf等。values获取所有的枚举的实例,也可以通过Class的getEnumConstants()方法获取所有实例。
由于所有的枚举都继承自Enum类,所以创建新的枚举类型时不能再继承某一个类,但可以实现多个接口,其使用方法与常规的类一致。
enum Signal implements Generator<Signal>{
GREEN, YELLOW, RED;
@Override
public Signal next() {
switch (this){
case RED: return GREEN;
case GREEN:return YELLOW;
case YELLOW:return RED;
default:
return RED;
}
}
public static <T> T printNext(Generator<T> g){
T t = g.next();
System.out.print(t + ",");
return t;
}
public static void main(String[] args){
Signal s = GREEN;
for(int i = 0; i < 10; i++){
s = printNext(s);
//YELLOW,RED,GREEN,YELLOW,RED,GREEN,YELLOW,RED,GREEN,YELLOW,
}
}
}
使用接口组织枚举
interface Food {
enum Appetizer implements Food{
SALAD, SOUP, SPRING_ROLLS
}
enum MainCourse implements Food{
LASAGNE,PAD_THAI,LENTIS
}
}
如上面的例子,这些枚举类型都可以向上转型成Food,但又有各自的类型。
EnumSet
EnumSet是专用用来存在枚举类型的Set。由于枚举类型的特殊性,EnumSet底层使用long来存储对应的枚举实例是否在Set中。long对应64位,所以如果枚举类型少于64位,则一个long即可存储,再多的话会使用多个long来存储。
EnumSet提供了众多的静态方法:
EnumSet<Signal> signals = EnumSet.noneOf(Signal.class);
signals.add(Signal.YELLOW);
System.out.println(signals); // [YELLOW]
signals.addAll(EnumSet.of(Signal.RED, Signal.GREEN));
System.out.println(signals); // [GREEN, YELLOW, RED]
signals = EnumSet.allOf(Signal.class);
System.out.println(signals); //[GREEN, YELLOW, RED]
signals.removeAll(EnumSet.of(Signal.RED));
System.out.println(signals); // [GREEN, YELLOW]
signals.removeAll(EnumSet.range(Signal.GREEN, Signal.RED));
System.out.println(signals); // []
signals = EnumSet.complementOf(signals);
System.out.println(signals); // [GREEN, YELLOW, RED]
EnumMap
EnumMap是一种特殊的Map,它要求其中的键必须是Enum。由于枚举的特殊性,EnumMap的内部可用数组来实现。
EnumMap遍历输出的顺序是枚举类型定义的顺序:
EnumMap<Signal, Integer> enumMap = new EnumMap<Signal, Integer>(Signal.class);
enumMap.put(Signal.RED, 1);
enumMap.put(Signal.RED, 2);
enumMap.put(Signal.GREEN, 3);
enumMap.put(Signal.YELLOW, 4);
System.out.println(enumMap); // {GREEN=3, YELLOW=4, RED=2}
常量相关的方法
可以为枚举定义一个抽象接口,而每一个枚举实例都实现这个方法:
enum LikeClasses{
WINKEN{
@Override
void behavior() {
System.out.println("behavior");
}
};
abstract void behavior();
}
其实这里会创建一个继承自LikeClasses的匿名类,WINKEN的类型就是这个类,当然由于向上转型的原因。WINKEN也是一个LikeClasses。
这通常被称为表驱动的代码(table-driven code)。
双重分发
在Java中,根据参数决定使用哪个方法是在编译时决定的,称之为静态分发。而由于多态的特性,运行时会找到指定类的方法运行,这称之为动态分发。
书中演示的例子使用静态分发和动态分发结合实现了双重分发,也使用了枚举类型的switch和常量相关方法来实现了双重分发,都一些基本的操作。
关于双重分发,在访问者模式中经常使用,可以参考设计模式。
第20章 注解
注解又称元信息,是在代码中添加信息使得可以在稍后某个时刻(编译或者运行时)可以方便地使用这些数据。
在Java SE5中内置了三种定义在java.lang下的注解:
@Override,表示当前方法定义将覆盖超类中的方法,如果对应的方法并没有覆盖超类的方法(拼写错误或者签名不匹配),则编译器会发出错误提醒。并非强制使用。
@Deprecated,表示对应的方法已经不推荐使用,如果使用了对应的方法,编译器将发出警告。
@SuppresWarnings,抑制编译器警告。
元注解
为了自定义注解,需要依赖于元注解。Java中有4种元注解:
@Target:表示注解可以用于的地方,值为枚举类型ElementType,可能的值有CONSTRUCTOR(构造器声明)、FIELD(域声明,包括enum实例)、LOCAL_VARIABLE(局部变量声明)、METHOD(方法声明)、PACKAGE(包声明)、PARAMETER(参数声明)、TYPE(类、接口、注解类型或者enum声明)、ANNOTATION_TYPE(专门用于注解)、TYPE_PARAMETER(1.8新加,用于泛型的类型参数)、TYPE_USE(1.8新加,在使用类型的声明中,这个值的范围包括TYPE_PARAMETER)
// 说明TYPE_USE和TYPE_PARAMETER的用法
public class MyMetaAnnotation<@InTypeParameter @InTypeUse T>{
public @InTypeUse T f(){
ArrayList<@InTypeUse Integer> t = new @InTypeUse ArrayList<>();
return null;
}
}
@Target({ElementType.TYPE_PARAMETER})
@interface InTypeParameter {}
@Target({ElementType.TYPE_USE})
@interface InTypeUse {}
@Retention:表示需要在什么级别保存此注解信息。值为RetentionPolicy类型,包括SOURCE(注解将被编译器丢弃)、CLASS(注解在class文件中可用,将被JVM丢弃)、RUNTIME(JVM也保留注解,可通过反射获取注解信息)
@Documented:将此注解包含于Javadoc中
@Inherited:允许子类继承父类中的注解
注解元素
注解类型可以添加成员,称之为注解元素。
其可用的类型包括所有的基本类型、String、Class、enum、Annotation以及这些类型的数组形式。
如果使用了这些类型以外的类型,编译器将会报错。注意也不允许使用包装类型。另外注解本身也可以做为元素类型,所以可以定义嵌套的注解。
除此之外,可以为元素提供一个默认值,注意没有提供默认值的元素必须在使用注解时指定。另外任何注解元素的值不能为null。
注解元素的value字段为特殊字段,如果某一个注解只要设置value值,则在使用时,可以省略value=这个标识。
如下定义了一个用于生成数据库建表语句的注解与对应的类。其中的表字段类型SQLInt和SQLString都嵌套了Constraints注解。
@DBTable("user")
class UserTable{
@SQLInt(value = "uid", constraints = @Constraints(primaryKey = true)) Integer uid;
@SQLString("name") String name;
}
/**
* 用于标识类为数据库并指定数据库名
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@interface DBTable{
String value();
}
/**
* 约束条件
*/
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
@interface Constraints{
boolean primaryKey() default false;
boolean allowNull() default false;
boolean unique() default false;
}
/**
* 字符串字段
*/
@Target(ElementType.FIELD)
@interface SQLString{
String value();
int size() default 10;
Constraints constraints() default @Constraints(allowNull = true);
}
/**
* 整形字段
*/
@Target(ElementType.FIELD)
@interface SQLInt{
String value();
Constraints constraints() default @Constraints(allowNull = true);
}
注解处理器
有了注解和使用注解的类型或者字段,就需要使用注解处理器来处理这些信息了。
以上面的数据库生成注解为例,实现一个通过以上注解生成建表语句的注解处理器:
public class DBAnnotation {
public static void main(String[] args){
Class<?> clz = UserTable.class;
DBTable dbTable = clz.getAnnotation(DBTable.class);
if (dbTable == null) {
throw new RuntimeException("No DBTable annotation in class!");
}
String tableName = dbTable.value();
List<String> columnDefs = new ArrayList<>();
for(Field field : clz.getDeclaredFields()){
Annotation[] annotations = field.getDeclaredAnnotations();
if(annotations.length < 1) continue;
if(annotations[0] instanceof SQLString){
SQLString sqlString = (SQLString)annotations[0];
columnDefs.add(sqlString.value() + " VARCHAR(" + sqlString.size() + ")" + getConstraints(sqlString.constraints()));
}else if(annotations[0] instanceof SQLInt){
SQLInt sqlInt = (SQLInt)annotations[0];
columnDefs.add(sqlInt.value()+ " INT " + getConstraints(sqlInt.constraints()));
}
}
String sql = "CREATE TABLE " + tableName + "(\n " + String.join(",\n ", columnDefs) + "\n);";
System.out.println(sql);
/**
* CREATE TABLE user(
* uid INT PRIMARY KEY NOT NULL,
* name VARCHAR(10)
* );
*/
}
public static String getConstraints(Constraints constraints){
String res = "";
if(constraints.primaryKey()){
res += " PRIMARY KEY ";
}
if(constraints.unique()){
res += " UNIQUE ";
}
if(!constraints.allowNull()){
res += " NOT NULL";
}
return res;
}
}
插入式注解处理(Pluggable Annotation Processing)
Java8 移除了APT(Annotation Processor Tools),而使用插入式注解API来处理注解。但其更强大的功能不仅是对注解的处理,而是在编译时提供了插件式自定义组件对Java的源代码进行检查,添加或者修改。
著名的Lombok就使用了插入式注解API为用户编写的类自动加入各种各样的get/set方法以及builder方法。
以下提供了对MyService注解的类注入get/set方法的例子,来自此
// MyApt.java
@SupportedAnnotationTypes("MyService")
//@SupportedAnnotationTypes("*")
@SupportedSourceVersion(SourceVersion.RELEASE_8)
public class MyApt extends AbstractProcessor {
private JavacTrees trees;
private TreeMaker treeMaker;
private Names names;
@Override
public synchronized void init(ProcessingEnvironment processingEnv) {
super.init(processingEnv);
this.trees = JavacTrees.instance(processingEnv);
Context context = ((JavacProcessingEnvironment) processingEnv).getContext();
this.treeMaker = TreeMaker.instance(context);
this.names = Names.instance(context);
}
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
roundEnv.getElementsAnnotatedWith(MyService.class).stream().map(element -> trees.getTree(element)).forEach(t -> t.accept(new TreeTranslator() {
@Override
public void visitClassDef(JCTree.JCClassDecl jcClassDecl) {
jcClassDecl.defs.stream().filter(k -> k.getKind().equals(Tree.Kind.VARIABLE)).map(tree -> (JCTree.JCVariableDecl) tree).forEach(jcVariableDecl -> {
//添加get方法
jcClassDecl.defs = jcClassDecl.defs.prepend(makeGetterMethodDecl(jcVariableDecl));
//添加set方法
jcClassDecl.defs = jcClassDecl.defs.prepend(makeSetterMethodDecl(jcVariableDecl));
});
super.visitClassDef(jcClassDecl);
}
}));
return true;
}
/**
* 创建get方法
*
* @param jcVariableDecl
* @return
*/
private JCTree.JCMethodDecl makeGetterMethodDecl(JCTree.JCVariableDecl jcVariableDecl) {
//方法的访问级别
JCTree.JCModifiers modifiers = treeMaker.Modifiers(Flags.PUBLIC);
//方法名称
Name methodName = getMethodName(jcVariableDecl.getName());
//设置返回值类型
JCTree.JCExpression returnMethodType = jcVariableDecl.vartype;
ListBuffer<JCTree.JCStatement> statements = new ListBuffer<>();
statements.append(treeMaker.Return(treeMaker.Select(treeMaker.Ident(names.fromString("this")), jcVariableDecl.getName())));
//设置方法体
JCTree.JCBlock methodBody = treeMaker.Block(0, statements.toList());
List<JCTree.JCTypeParameter> methodGenericParams = List.nil();
List<JCTree.JCVariableDecl> parameters = List.nil();
List<JCTree.JCExpression> throwsClauses = List.nil();
//构建方法
return treeMaker.MethodDef(modifiers, methodName, returnMethodType, methodGenericParams, parameters, throwsClauses, methodBody, null);
}
/**
* 创建set方法
*
* @param jcVariableDecl
* @return
*/
private JCTree.JCMethodDecl makeSetterMethodDecl(JCTree.JCVariableDecl jcVariableDecl) {
try {
//方法的访问级别
JCTree.JCModifiers modifiers = treeMaker.Modifiers(Flags.PUBLIC);
//定义方法名
Name methodName = setMethodName(jcVariableDecl.getName());
//定义返回值类型
JCTree.JCExpression returnMethodType = treeMaker.Type((Type) (Class.forName("com.sun.tools.javac.code.Type$JCVoidType").newInstance()));
ListBuffer<JCTree.JCStatement> statements = new ListBuffer<>();
statements.append(treeMaker.Exec(treeMaker.Assign(treeMaker.Select(treeMaker.Ident(names.fromString("this")), jcVariableDecl.getName()), treeMaker.Ident(jcVariableDecl.getName()))));
//定义方法体
JCTree.JCBlock methodBody = treeMaker.Block(0, statements.toList());
List<JCTree.JCTypeParameter> methodGenericParams = List.nil();
//定义入参
JCTree.JCVariableDecl param = treeMaker.VarDef(treeMaker.Modifiers(Flags.PARAMETER, List.nil()), jcVariableDecl.name, jcVariableDecl.vartype, null);
//设置入参
List<JCTree.JCVariableDecl> parameters = List.of(param);
List<JCTree.JCExpression> throwsClauses = List.nil();
//构建新方法
return treeMaker.MethodDef(modifiers, methodName, returnMethodType, methodGenericParams, parameters, throwsClauses, methodBody, null);
} catch (Exception e) {
System.err.println(e);
}
return null;
}
private Name getMethodName(Name name) {
String s = name.toString();
return names.fromString("get" + s.substring(0, 1).toUpperCase() + s.substring(1, name.length()));
}
private Name setMethodName(Name name) {
String s = name.toString();
return names.fromString("set" + s.substring(0, 1).toUpperCase() + s.substring(1, name.length()));
}
}
//MyService.java
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface MyService {
String value() default "";
}
// Main.java
public class Main {
public static void main(String[] args){
POJO pojo = new POJO(10);
System.out.println(pojo.getId());
}
}
@MyService()
class POJO {
private int id;
public POJO(int id) {
this.id = id;
}
}
运行方式:
进入对应的目录,先编译MyApt这一注解处理器:javac MyApt.java MyService.java,如果没有设置classpath需要指定classpath把tools.jar引入。
然后编译Main.java,指定注解处理器:javac -processor MyApt Main.java MyService.java,编译通过之后就可以运行对应的class文件了:java Main,可以看到输出了10。
第21章 并发
基本的线程机制
简单使用
public class Simple {
public static void main(String[] args){
Thread t = new Thread(new Print());
// setDaemon是用来设置线程为后台线程,默认线程都为非后台线程。
// 只有当所有非后台线程都退出后,主线程才结束。
// t.setDaemon(true);
// 设置线程的级别,为了避免不同平台的差异,推荐使用MAX_PRIORITY、NORM_PIORITY、MIN_PRIORITY
t.setPriority(Thread.MAX_PRIORITY);
t.start();
System.out.println("main");
}
static class Print implements Runnable{
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(5);
// 或者使用以下语句可以达到同样的效果
//Thread.sleep(5000);
}catch (InterruptedException e){
e.printStackTrace();
}
System.out.println("thread");
// yield用于给调度暗示,表明当前线程已经完成重要工作,这时正是换出cpu的好时机。但这也只是给一个暗示,具体操作还和其它的因素有关。
Thread.yield();
}
}
}
使用Executor
java.util.concurrent提供了执行器(Executor)来管理Thread对象。Executor是一个接口,拥有void execute(Runnable command)方法。
ExecutorService是具有生命周期的Executor,可以通过submit、shutdown等方法来管理任务的执行和取消。
Executors类提供了创建各种执行器的方法,他除了提供创建Executor、ExecutorService对象的方便方法外,还可以创建ScheduledExecutorService、ThreadFactory、Callable等等。
以下例子创建了三种不同的ExecutorService,并试验了其行为:
public class MyExecutor implements Runnable {
public static void main(String[] args) throws InterruptedException {
ExecutorService service = Executors.newCachedThreadPool();
service.submit(new MyExecutor());
service.submit(new MyExecutor());
TimeUnit.SECONDS.sleep(2);
service.submit(new MyExecutor());
service.submit(new MyExecutor());
TimeUnit.SECONDS.sleep(2);
service.shutdown();
// 以上输出为10,11,11,10,说明后两执行复用了前两的线程
ExecutorService serviceFix = Executors.newFixedThreadPool(2);
for (int i = 0; i < 10; i++) {
serviceFix.submit(new MyExecutor());
}
TimeUnit.SECONDS.sleep(2);
serviceFix.shutdown();
// 输出13,14,13,14,13,14,13,14,13,14,说明serviceFix只起了13、14两个线程来执行
ExecutorService serviceSingle = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
serviceSingle.submit(new MyExecutor());
}
TimeUnit.SECONDS.sleep(2);
serviceSingle.shutdown();
// 输出为15,15,15,15,15,15,15,15,15,15,SingleThreadExecutor是数量为1的FixedThreadPool
}
@Override
public void run() {
System.out.print(Thread.currentThread().getId() + ",");
}
}
如果需要从线程执行任务中返回对象,则需要使用Callable来代替Runnable接口。
final static class MyCallable implements Callable<Long>{
@Override
public Long call(){
return Thread.currentThread().getId();
}
}
用法与Runnable一样,只是在submit的时候会立即返回一个Future对象。这个Future对象可以查询到任务的运行状态(isDone/isCancle),也可以取消运行(cancle)。最主要的是可以通过get方法获取任务的返回值,如果任务还没有执行完成,get将阻塞,直到任务完成。
ExecutorService serviceCallable = Executors.newCachedThreadPool();
Future<Long> future = serviceCallable.submit(new MyCallable());
try {
System.out.print(future.isDone()+",");
System.out.print(future.get()+",");
}catch (ExecutionException e){
e.printStackTrace();
}
serviceCallable.shutdown();
serviceCallable.awaitTermination(2, TimeUnit.SECONDS);
// 输出false,16,
上面这个例子中等待线程执行完成并退出使用的awaitTermination函数,这个函数在所有线程正常退出时返回true,如果超时,则返回false。
如果要定制化ExecutorService里的线程属性,则可以使用ThreadFactory来处理。
public class MyFactory implements ThreadFactory {
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setDaemon(true);
t.setName("thread-my");
return t;
}
public static void main(String[] args) throws InterruptedException{
ExecutorService threadService = Executors.newCachedThreadPool(new MyFactory());
threadService.submit(() -> System.out.println(Thread.currentThread().getName()));
TimeUnit.SECONDS.sleep(1);
// 输出为thread-my,并且在没有调用shutdown的情况下,主线程退出了,说明所创建的线程都为daemon线程
}
}
需要注意的是从daemon线程再创建的线程,默认就是daemon。
Thread t = new Thread(()->{
new Thread(()->System.out.println(Thread.currentThread().isDaemon())).start();
});
t.setDaemon(true);
t.start();
interrupt
interrupt方法会在对应线程上设置中断标志,表明此线程已经中断,然而异常被捕获时将清理这个标志。
这个中断可以打断wait、sleep、join等方法调用,使其抛出InterruptedException异常;也可以中断InterruptibleChannel上的I/O操作,抛出ClosedByInterruptException异常;对于阻塞在Selector上的操作,会使得此操作直接返回,就像有事件发生一样。
public class MyInterrupt extends Thread {
private int duration;
public MyInterrupt(String name, int duration) {
super(name);
this.duration = duration;
this.start();
}
@Override
public void run() {
try{
System.out.println(currentThread().getName() + ":start sleep");
TimeUnit.SECONDS.sleep(duration);
}catch (InterruptedException e){
System.out.println(currentThread().getName() + ":" + e.getMessage());
System.out.println(currentThread().getName() + " is interrepted:" + currentThread().isInterrupted());
}
}
public static void main(String[] args)throws InterruptedException{
MyInterrupt myInterrupt = new MyInterrupt("myjoin", 10);
TimeUnit.SECONDS.sleep(1);
myInterrupt.interrupt();
System.out.println("thread isInterrupt:" + myInterrupt.isInterrupted());
TimeUnit.SECONDS.sleep(1);
// 返回结果
// myjoin:start sleep
// thread isInterrupt:true
// myjoin:sleep interrupted
// myjoin is interrepted:false
}
}
这个例子也显示了另外一种新建线程的方法,即继承Thread类,并重写run方法。
如果使用了ExecutorService,可以对返回的Future对象调用cancle方法来中断任务执行。
ExecutorService executorService = Executors.newCachedThreadPool();
Future<?> f = executorService.submit(
() -> {
while (true){
try{
TimeUnit.SECONDS.sleep(10);
}catch (InterruptedException e){
System.out.println("get a interrupted exception:" + e.getMessage());
break;
}
}
System.out.println("task stop!");
}
);
TimeUnit.SECONDS.sleep(1);
f.cancel(true);
TimeUnit.SECONDS.sleep(1);
executorService.shutdown();
// get a interrupted exception:sleep interrupted
// task stop!
如果线程中没有可中断的调用,那要让线程退出就要用到isInterrupted这个状态的判断,即需要手动书写处理这个状态的代码。
join
调用某个线程的join方法,则需要等待此线程完全执行完成后这个join方法才会返回。join支持时间参数,可以指定需要等待的最长时间。
public class MyJoin extends Thread {
private Thread t;
public MyJoin(String name, Thread t) {
super(name);
this.t = t;
this.start();
}
@Override
public void run() {
try {
if(t != null){
t.join();
}
System.out.println(currentThread().getName() + ":start sleep");
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
System.out.println(currentThread().getName() + ":" + e.getMessage());
}
System.out.println(currentThread().getName() + ":sleep done");
}
public static void main(String[] args) throws InterruptedException {
MyJoin myJoin1 = new MyJoin("thread 1", null);
MyJoin myJoin2 = new MyJoin("thread 2", myJoin1);
// 结果
// thread 1:start sleep
// thread 1:sleep done
// thread 2:start sleep
// thread 2:sleep done
}
}
捕获异常
public static void main(String[] args){
Thread t = new Thread(() -> {
throw new RuntimeException();
});
try {
t.start();
t.join();
}catch (Exception e){
System.out.println("catch a Exception");
}
System.out.println("main thread end");
}
如上main函数,运行结果为:
Exception in thread "Thread-0" java.lang.RuntimeException
at mythread.MyException.lambda$main$0(MyException.java:6)
at java.lang.Thread.run(Thread.java:748)
main thread end
可见线程里的异常无法在另外一个线程中捕获,也不会影响另外一线程的运行。
如果要捕获线程中逃逸出run方法的异常,可以通过设置uncaughtExceptionHandler来解决问题:
public static void main(String[] args){
Thread.setDefaultUncaughtExceptionHandler(new ThreadExceptionHandler());
new Thread(() -> {
throw new RuntimeException("my runtime exception");
}).start();
// Thread-1 caught a exception:my runtime exception
}
final static class ThreadExceptionHandler implements Thread.UncaughtExceptionHandler{
@Override
public void uncaughtException(Thread t, Throwable e) {
System.out.println(t.getName() + " caught a exception:" + e.getMessage());
}
}
可以通过静态函数Thread.setDefaultUncaughtExceptionHandler来设置全局默认的异常处理器,也可以通过调用线程上的setUncaughtExceptionHandler方法来设置这个线程的异常处理器。
共享受限资源
synchronized
使用synchronized可以解决共享资源竞争问题。
对象方法上的synchronized
所有对象上自动含有单一的锁(也称为监视器)。在对象上调用任意synchronized修饰的方法时,此对象会加锁,并在方法调用完成之后释放锁。如果加锁失败,则阻塞等待。
一个任务可以多次获取对象的锁,实质上是对锁进行计数。当然只有同一个任务(线程)才能在同一个对象上多次加锁。
public class MySync {
private int counter = 0;
public synchronized void incr(){
counter++;
}
public int get(){
return counter;
}
public static void main(String[] args) throws InterruptedException{
ExecutorService threadService = Executors.newFixedThreadPool(10);
MySync mySync = new MySync();
for(int i = 0; i< 1000; i++){
threadService.submit(()->mySync.incr());
}
TimeUnit.SECONDS.sleep(2);
System.out.println(mySync.get());
threadService.shutdown();
}
}
如果没有在incr方法上添加synchronized关键字,则每一次运行的结果都有可能不一样。因为在java中++操作符并不是原子的。
静态方法上的synchronized
之前说了每一个对象有一个锁,而同样的对于每一个类,也有一把锁,它是类的Class对象的一部分,所以对静态方法修饰synchronized将在类范围内防止对static数据进行并发访问。
同步控制块
如果只对某一部分的代码进行同步控制,则可以使用synchronized指定某一个对象来实现。注意这个synchronized锁住对象使用的锁,与对象方法里使用的对象锁是同一个。
class MySync1 {
public synchronized void f() {
System.out.println("f start");
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("f end");
}
public static void main(String[] args) {
MySync1 mySync1 = new MySync1();
new Thread(() -> mySync1.f()).start();
synchronized (mySync1) {
System.out.println("main in sync");
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("main end");
}
// 输出如下,说明synchronized同步控制块与方法上使用的对象锁为同一个
// main in sync
// main end
// f start
// f end
}
}
显示使用Lock对象
使用java.util.concurrent.locks下面的锁也可以达到synchronized的效果。需要注意的是,如果在try-catch中对锁进行操作,那么在finally中解锁将是一个值得考虑的方式,它有效避免了在异常时刻无法正确解锁的问题。
public class MyLock {
private int counter = 0;
private Lock lock = new ReentrantLock();
public void incr(){
lock.lock();
counter++;
lock.unlock();
}
public int get(){
return counter;
}
}
locks库中提供了更多关于锁的功能,例如tryLock可以尝试获取锁,并立即返回或者在一段时间内尝试获取锁等等功能。
此外还提供了ReentrantLock、ReadWriteLock等多种锁可供使用。
对于lock阻塞,正常是无法通过interrupt来中断的。如果确实需要使用interrupt来中断,可以使用lockInterruptibly方法。
原子性
原子操作无法被线程调度机制中断的操作,即一旦操作开始,则一定会在上下文切换前执行完毕。
Java中,除了long和double外的所有基本类型的读取和写入操作都为原子操作。long和double在某些JVM实现上会被分离成两个32位来操作,在些期间可以被调度切换出去,导致看到部分修改的中间结果,这被称之为字撕裂。
在Java5之后,对于long和double类型的变量,如果添加了volatile修饰,则对应变量的读写操作也是原子的。
如果之前看到的例子,++操作并非原子操作,这一点可以通过字节码很容易得到验证。与此类似+=等操作也非原子操作。
Java5中还引入了AtomicInteger、AtomicLong、AtomicReference等特殊的原子性变量类,提供了cas操作以及其它的原子操作。
public class MyAtomic {
private AtomicInteger counter;
public void incr(){
counter.addAndGet(1);
}
public int get(){
return counter.get();
}
}
对于cas操作,在某些乐观锁/自旋以及锁优化上发挥了重要作用。
private AtomicBoolean lock;
public void lock(){
while (lock.compareAndSet(false, true));
}
public void unlock(){
lock.compareAndSet(true, false);
}
可见性
现在计算机结构中都使用了多级缓存来加速程序的运行,所以一个线程对某一个变量的写入操作,在另外一个线程中无法立刻读取出来,这就是可见性问题。
使用volatile关键字可以确保应用中的可见性。其原理是在volatile修改的域在操作时,会立即写入到主存中,而读取操作也会直接从主存中读取。但具体细节上还有指令重排、内存屏障和缓存同步机制等多方面的因素,具体可以参考其它资料。
public class Singleton {
private volatile static Singleton instance;
private Singleton() {}
public static Singleton getSingleton() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
此文可以帮助更好的理解volatile的作用。
线程本地存储
ThreadLoal对象提供了线程本地存储的能力,我们看以下例子:
public class MyThreadLocal {
public static void main(String[] args) {
for (int i = 0; i < 2; i++) {
new Thread(() -> {
MyThreadLocal.counter.set(1);
for (int j = 0; j < 10; j++) {
System.out.println(Thread.currentThread().getName() + ":" + MyThreadLocal.counter.get());
Thread.yield();
MyThreadLocal.counter.set(MyThreadLocal.counter.get() + 1);
}
}).start();
}
// Thread-0:1
// Thread-0:2
// Thread-1:1
// Thread-0:3
// Thread-1:2
// Thread-0:4
// Thread-1:3
// Thread-0:5
// Thread-1:4
// Thread-0:6
// Thread-1:5
// Thread-0:7
// Thread-1:6
// Thread-0:8
// Thread-1:7
// Thread-0:9
// Thread-1:8
// Thread-0:10
// Thread-1:9
// Thread-1:10
}
static ThreadLocal<Integer> counter = new ThreadLocal<>();
}
虽然是共享的ThreadLocal对象,但是不同线程对其进行操作,不会互相影响。
wait、notify、notifyAll
Object对象提供了wait、notify、notifyAll这三个方法,这些方法只能在使用synchronized方法或者代码块中调用,否则在在运行时会抛出IllegalMonitorStateException异常,并报告当前线程不是拥有者这一错误。
wait的作用是在使得对应线程挂起,直到notify或者notifyAll调用,对应线程才被唤醒。wait支持时间参数,可以设置等待的最长时间。
注意在wait调用后,此线程持有的此对象的锁将被释放。对应地在被唤醒之后,需要重新获得锁才能继续执行。
notify与notifyAll的区别是notify只能阻塞在对应对象上的一个线程,而notifyAll将把有阻塞在对应对象上的线程都唤醒。
public class NotifyQueue<T> {
T tmp = null;
public synchronized T get(){
while (tmp == null){
try {
wait();
}catch (InterruptedException e){
e.printStackTrace();
}
}
T t = tmp;
tmp = null;
return t;
}
public synchronized void set(T t){
tmp = t;
notify();
}
public static void main(String[] args) throws InterruptedException{
NotifyQueue<Integer> notifyQueue = new NotifyQueue<>();
ExecutorService executorService = Executors.newCachedThreadPool();
for(int i = 0; i< 5; i++){
executorService.submit(()->{
while(true){
System.out.println(Thread.currentThread().getName() + " get:" + notifyQueue.get());
}
});
}
while(true){
System.out.println("set value");
notifyQueue.set(10);
TimeUnit.SECONDS.sleep(1);
}
// pool-1-thread-4 get:10
// set value
// pool-1-thread-5 get:10
// set value
// pool-1-thread-2 get:10
// set value
// pool-1-thread-1 get:10
// set value
// pool-1-thread-3 get:10
// set value
// pool-1-thread-4 get:10
}
}
以上程序使用wait和notify实现了类似channel的功能,get操作将阻塞,直到有其它线程set了值。
在wait中唤醒时,需要再次检查条件是否满足,如果不满足(可能原因是被唤醒的其它线程修改,或者是其它程序的其它部分修改),需要再次进入wait状态。
另外wait的条件判断一定需要放置在synchronized同步控制块中,否则会导致错失的notify信号,例如以下的例子:
// Thread 1
synchronized(shareMonitor){
<setup condition for T2>
sharedMonitor.notify();
}
// Thread2
while(someCondition){ // 需要将此条件放入到synchronized中
synchronized(shareMonitor){
shareMonitor.wait();
}
}
Condition与Lock
之前的synchronized和wait、notify的组合,可以使用Lock和Condition来代替:
public class ConditionQueue<T> {
private T tmp = null;
private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
public T get(){
lock.lock();
try {
while (tmp == null) {
try {
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = tmp;
tmp = null;
return t;
}finally {
lock.unlock();
}
}
public void set(T t){
lock.lock();
try {
tmp = t;
condition.signal();
}finally {
lock.unlock();
}
}
public static void main(String[] args) throws InterruptedException{
ConditionQueue<Integer> notifyQueue = new ConditionQueue<>();
ExecutorService executorService = Executors.newCachedThreadPool();
for(int i = 0; i< 5; i++){
executorService.submit(()->{
while(true){
System.out.println(Thread.currentThread().getName() + " get:" + notifyQueue.get());
}
});
}
while(true){
System.out.println("set value");
notifyQueue.set(10);
TimeUnit.SECONDS.sleep(1);
}
// pool-1-thread-4 get:10
// set value
// pool-1-thread-5 get:10
// set value
// pool-1-thread-2 get:10
// set value
// pool-1-thread-1 get:10
// set value
// pool-1-thread-3 get:10
// set value
// pool-1-thread-4 get:10
}
}
Condition提供await和singal/singalAll的方法与wait和notify/notifyAll类似。
BlockingQueue
相对于之前两个简陋的阻塞队列,Java中提供了BlockingQueue接口,它不仅实现了Queue接口,而且添加了pool、take、put等方法来进行阻塞获取和添加操作。
实现BlockingQueue的类有多个,我们依次介绍。
public static void test(BlockingQueue<Integer> queue){
// 生产者
new Thread(()->{
while (true) {
try {
Integer v = new Random().nextInt(100);
queue.put(v);
System.out.println("put a value:" + v);
TimeUnit.MILLISECONDS.sleep(100);
}catch (InterruptedException e){
e.printStackTrace();
break;
}
}
}).start();
// 消费者
while (true){
try{
Integer v = queue.take();
System.out.println("take a value:" + v);
TimeUnit.MILLISECONDS.sleep(500);
}catch (InterruptedException e){
e.printStackTrace();
break;
}
}
}
以上是模拟了生产者和消费者模型,用于测试各种BlockingQueue的行为。
LinkedBlockingQueue
底层使用链表来实现的阻塞队列,可以指定队列的容量,如果超过容量时put操作将阻塞,直到容量释放。如果不指定容量,则为Integer.MAX_VALUE。
test(new LinkedBlockingQueue<>());
这个测试的输出保持5个put和1个take的节奏,不会因为消费慢而阻塞(当然当超过Integer.MAX_VALUE时会阻塞)。
put a value:1
take a value:1
put a value:10
put a value:40
put a value:37
put a value:14
take a value:10
put a value:36
put a value:15
put a value:1
put a value:92
put a value:31
take a value:40
put a value:92
put a value:82
put a value:13
put a value:19
put a value:10
take a value:37
...
ArrayBlockingQueue
底层使用数组实现,需要指定容量,超过容量时put操作将阻塞。
test(new ArrayBlockingQueue<>(2));
从以下结果可以看出,在达到容量时,put操作就会出现阻塞,等待有人take取走元素之后put才能成功反回。
put a value:71
take a value:71
put a value:68
put a value:62
put a value:27
take a value:68
take a value:62
put a value:91
take a value:27
put a value:94
take a value:91
put a value:56
take a value:94
put a value:63
take a value:56
put a value:97
take a value:63
ArrayBlockingQueue的构造函数还支持fair参数,用于指定队列的出入元素顺序是否遵循FIFO原则,默认为false。
SynchronousQueue
这是一个特殊的阻塞队列,他没有容量,更准确的说对SynchronousQueue进行put操作时将阻塞,只有另外一个线程进行take或者对应获取操作时put才会成功返回。
PipedWriter和PipedReader
这里的例子虽然没有演示了两个线程使用pipe通信的情况,但与在同一个线程中使用相似。
public class Pipe {
public static void main(String[] args) throws IOException {
PipedReader pipedReader = new PipedReader();
PipedWriter pipedWriter = new PipedWriter();
pipedWriter.connect(pipedReader);
pipedWriter.write("ABCDEFG");
while(true) {
System.out.print((char)pipedReader.read());
}
// ABCDEFG
}
}
CountDownLatch
CountDownLatch创建时指定任务数,在任务完成时调用countDown,将计数减1,等减到0时,阻塞在await上的线程将被唤醒。与go的WaitGroup类似。
public class MyCountDwonLatch {
public static void main(String[] args){
int size = 10;
CountDownLatch countDownLatch = new CountDownLatch(size);
for(int i = 0; i< size; i++){
new Thread(()->{
try {
TimeUnit.SECONDS.sleep(1);
}catch (InterruptedException e){
e.printStackTrace();
}
System.out.print("job done,");
countDownLatch.countDown();
}).start();
}
try {
countDownLatch.await();
}catch (InterruptedException e){
e.printStackTrace();
}
System.out.println("job all done");
// job done,job done,job done,job done,job done,job done,job done,job done,job done,job done,job all done
}
}
CyclicBarrier
CyclicBarrier适用于这种场景,一组任务中每一个任务都有两个子任务,需要大家都做完第一个子任务的时候才能做第二个子任务。
public class MyCylicBarrier {
public static void main(String[] args){
int size = 10;
CyclicBarrier barrier = new CyclicBarrier(size, ()->{
System.out.println("barrier action done");
});
for(int i = 0; i< size; i++){
new Thread(()->{
try{
TimeUnit.SECONDS.sleep(1);
System.out.println("task done");
barrier.await();
System.out.println("task await done");
}catch (InterruptedException e){
e.printStackTrace();
}catch (BrokenBarrierException e){
e.printStackTrace();
}
}).start();
}
// task done
// task done
// task done
// task done
// task done
// task done
// task done
// task done
// task done
// task done
// barrier action done
// task await done
// task await done
// task await done
// task await done
// task await done
// task await done
// task await done
// task await done
// task await done
// task await done
}
}
构造函数还支持一个Runnable参数,在第一个子任务执行完成的时候会被调用。
DelayQueue
DelayQueue这一个泛型容器所能保存的元素必须实现Delayed接口。Delayed本身带了getDelay函数必须实现,另外这个接口继承自Comparable接口,所以也必须实现compareTo方法。
那么问题来了,一般我们认为延迟队列,实现方式为:在将元素加入队列的时候指定一个延迟,然后使用最小堆把最早触发的元素放在堆顶,之后就休眠到这个元素触发的时间,接着从堆顶取出元素即可,可以参考一下go的计时器的实现。
按照这种思路的话,getDelay就是返回延迟的时间,比如要1秒后执行就返回1秒。那这个Comparable就完全想不通其含义了,莫非是对于延迟时间一致时决定取出顺序?
但Java中的DelayQueue思路完全不同。底层确实用到优先队列(最小堆),但处于栈顶的,并非是触发时间最早的,而是按照compareTo方法比较结果最小的,也就是说compareTo完全决定了元素的取出顺序,与延迟大小无关。
那这个getDelay有啥用呢?首先这个getDelay并非入队时的时间延迟,而是一个动态计算的结果,即距离触发的时间,如果为0或者负数,则说明到时间了,位于堆顶的元素可以被取出了。
先看以下例子来加深理解:
public class MyDelayQueue {
public static void main(String[] args){
DelayQueue<MyDelayed> delayQueues = new DelayQueue<>();
for (int i = 0; i< 10; i++){
delayQueues.put(new MyDelayed( i* 1000));
}
for(int i = 0; i< 10; i++){
try {
MyDelayed myDelayed = delayQueues.take();
System.out.println(myDelayed);
}catch (InterruptedException e){
e.printStackTrace();
}
}
// id : 0, delay : 0
// id : 1, delay : 1000
// id : 2, delay : 2000
// id : 3, delay : 3000
// id : 4, delay : 4000
// id : 5, delay : 5000
// id : 6, delay : 6000
// id : 7, delay : 7000
// id : 8, delay : 8000
// id : 9, delay : 9000
}
static class MyDelayed implements Delayed {
private long triggerTime; // in milliseconds
private long delay; // in milliseconds
private static int counter;
private int id = counter++;
public MyDelayed(long delay) {
this.delay = delay;
this.triggerTime = delay + System.nanoTime() / 1000000L;
}
@Override
public long getDelay(TimeUnit unit) {
return unit.convert(triggerTime - System.nanoTime()/1000000L, TimeUnit.MILLISECONDS);
}
@Override
public int compareTo(Delayed o) {
long delta = this.getDelay(TimeUnit.MILLISECONDS) - o.getDelay(TimeUnit.MILLISECONDS) ;
return delta == 0 ? 0 : (delta > 0 ? 1 : -1);
}
@Override
public String toString(){
return String.format("id : %d, delay : %d", id, delay);
}
}
}
这是一个正常的实现方式,compareTo使用延迟时间来做排序,每秒打印一条信息。如果我们把compareTo换成了如下代码,即完全按id来倒序排列,即延迟最长的放最前面:
@Override
public int compareTo(Delayed o) {
return ((MyDelayed)o).id - this.id;
}
这个现象就有趣了,在前10秒没有任何输出,但在第10秒时将10个结果一起输出了:
id : 9, delay : 9000
id : 8, delay : 8000
id : 7, delay : 7000
id : 6, delay : 6000
id : 5, delay : 5000
id : 4, delay : 4000
id : 3, delay : 3000
id : 2, delay : 2000
id : 1, delay : 1000
id : 0, delay : 0
PriorityBlockingQueue
与优先队列一致,只是是读阻塞的。由于之前优先队列也没有例子,这里补全。
如果优先队列(阻塞优先队列)保存的元素实现了Comparable接口,则使用Comparable来实现优先排序。由于基本类型都实现了Comparable接口,所以都可以直接做为优先队列的元素。
public class MyPriorityBlockingQueue {
public static void main(String[] args){
PriorityBlockingQueue<MyItem> queue = new PriorityBlockingQueue<>(10, );
for(int i = 0; i< 10; i++){
queue.add(new MyItem());
}
for(int i = 0; i< 10; i++){
queue.add(i);
}
while (true) {
try {
System.out.println(queue.take());
}catch (InterruptedException e){
e.printStackTrace();
}
}
// id: 0
// id: 1
// id: 2
// id: 3
// id: 4
// id: 5
// id: 6
// id: 7
// id: 8
// id: 9
}
static class MyItem implements Comparable<MyItem> {
private static int counter;
private int id = counter++;
@Override
public int compareTo(MyItem o) {
return id - o.id;
}
@Override
public String toString(){
return "id: " + id;
}
}
}
如果保存的元素没有实现Comparable呢?那可以在优先队列的构造函数中传入Comparator来实现对元素的比较:
class MyItem2{
private static int counter;
private int id = counter++;
public int getId(){
return id;
}
@Override
public String toString(){
return "id: " + id;
}
public static void main(String[] args) {
PriorityBlockingQueue<MyItem2> queue = new PriorityBlockingQueue<>(10, new MyItem2Comparator());
for (int i = 0; i < 10; i++) {
queue.add(new MyItem2());
}
while (true) {
try {
System.out.println(queue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class MyItem2Comparator implements Comparator<MyItem2>{
@Override
public int compare(MyItem2 o1, MyItem2 o2) {
return o1.getId() - o2.getId();
}
}
如果即没有实现Comparable也没有提供Comparator,那么将抛出ClassCastException异常。
ScheduledThreadPoolExecutor
public class MyScheduledExecutor {
public static void main(String[] args){
ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(2);
executor.schedule(()->System.out.println("schedule !!"), 1, TimeUnit.SECONDS);
executor.scheduleAtFixedRate(()->System.out.println("scheduleAtFixedRate"), 2, 1, TimeUnit.SECONDS);
executor.scheduleWithFixedDelay(()->System.out.println("scheduleWithFixedDelay"), 3, 1, TimeUnit.SECONDS);
}
}
提供了延迟执行任务和间歇执行任务的函数,其中schedule可以在指定时间之后执行Action,而scheduleAtFixedRate和scheduleWithFixedDelay这两个函数都会在initialDelay时间之后开始按delay间歇性地执行Action,所不同的是前者不管动作执行时间的长短,固定间隔,但也不会并行,后者是按上一个执行结束之后再延迟delay来再次执行。
Semaphore
信号量Semaphore与锁不同之处在于锁在任何时刻都只允许一个任务访问一项资源(ReadWriteLock可以多个人持有读锁,实现方式与信号量类似),而计数信号量允许多个任务同时访问这个资源。
public class MySemaphore {
public static void main(String[] args){
Semaphore semaphore = new Semaphore(2);
new Thread(()->{
for(;;){
try{
semaphore.acquire();
System.out.println("acquire");
TimeUnit.MILLISECONDS.sleep(1000);
}catch (InterruptedException e){
e.printStackTrace();
}
}
}).start();
new Thread(()->{
for(;;){
try{
TimeUnit.MILLISECONDS.sleep(2000);
semaphore.release();
System.out.println("release");
}catch (InterruptedException e){
e.printStackTrace();
}
}
}).start();
}
}
刚开始两次的acquire可以成功,但后面的acquire必须阻塞等待有人release后才能再次成功返回。
Exchanger
Exchanger用于两个线程之间交换数据,先调用Exchanger.exchange的一方将阻塞等待另一方调用后才可返回,实现这两方的数据交换。
CopyOnWriteArrayList与CopyOnWriteArraySet
这两个容器类分别实现了线程安全的List和Set,其实现原理与其名字一样,就是在修改元素时,复制出一个新的数组来,具体我们以CopyOnWriteArrayList为例。
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
/**
* Inserts the specified element at the specified position in this
* list. Shifts the element currently at that position (if any) and
* any subsequent elements to the right (adds one to their indices).
*
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public void add(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
if (index > len || index < 0)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+len);
Object[] newElements;
int numMoved = len - index;
if (numMoved == 0)
newElements = Arrays.copyOf(elements, len + 1);
else {
newElements = new Object[len + 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index, newElements, index + 1,
numMoved);
}
newElements[index] = element;
setArray(newElements);
} finally {
lock.unlock();
}
}
/**
* {@inheritDoc}
*
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
return get(getArray(), index);
}
/**
* Gets the array. Non-private so as to also be accessible
* from CopyOnWriteArraySet class.
*/
final Object[] getArray() {
return array;
}
/**
* Sets the array.
*/
final void setArray(Object[] a) {
array = a;
}
从上面的代码可以看出,在add操作时,添加锁,并且复制出一个新的数据组来(System.arraycopy和Arrays.copyOf),将元素添加进新的数组,最后调用setArray进行替换。
对于引用的获取和赋值在Java中是原子的,可参考此,所以在get操作时,getArray不加锁并不会出现原子问题。可见性和防止指令重排的保证使用的是array属性的volatile修饰关键字来保证。
所以这个容器的使用场景也很明了,那些遍历、获取元素等场景远多于添加修改元素的场景就可以使用CopyOnWriteArrayList与CopyOnWriteArraySet,当然,前提是在多线程情况下使用。
ConcurrentHashMap
线程安全的HashMap,使用了slot技术来实现get操作无锁,put操作使用了cas和synchronized来使其线程安全。
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code key.equals(k)},
* then this method returns {@code v}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* @throws NullPointerException if the specified key is null
*/
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
第12章 图形化用户界面
略